Il Common Security Advisory Framework (CSAF) è un sistema progettato per fornire avvisi di sicurezza leggibili dalle macchine attraverso un processo standardizzato che facilita la condivisione automatizzata delle informazioni sulla sicurezza informatica. Greenbone sta attivamente lavorando per integrare tecnologie basate sullo standard CSAF 2.0 con l’obiettivo di automatizzare gli avvisi di sicurezza informatica. Per un’introduzione a CSAF 2.0 e una panoramica dei benefici che apporta alla gestione delle vulnerabilità, ti invitiamo a consultare il nostro .

Nel 2024, l’interruzione del NIST National Vulnerabilities Database (NVD) ha di dati critici verso i consumatori a valle, sottolineando la necessità di soluzioni più resilienti e distribuite. Il modello CSAF 2.0 decentralizzato si dimostra particolarmente rilevante in questo contesto, offrendo un quadro di condivisione delle informazioni che elimina la dipendenza da un singolo punto di errore. Grazie alla sua capacità di aggregare dati da una varietà di fonti affidabili, CSAF 2.0 garantisce una continuità operativa e una maggiore affidabilità nella distribuzione degli avvisi di sicurezza.
Indice
1. Di cosa parleremo in questo articolo
2. Chi sono gli stakeholder di CSAF?
2.1. I ruoli nel protocollo CSAF 2.0
2.1.1. Soggetti emittenti di CSAF 2.0
2.1.1.1. Il ruolo di editore di CSAF
2.1.1.2. Il ruolo di fornitore di CSAF
2.1.1.3. Il ruolo di trusted-provider di CSAF
2.1.2. Aggregatori di dati CSAF 2.0
2.1.2.1. Il ruolo di lister CSAF
2.1.2.2. Il ruolo di aggregatore CSAF
3. Conclusione
1. Di cosa parleremo in questo articolo
Questo articolo vuole approfondire quali sono gli stakeholder e i ruoli definiti nella specifica CSAF 2.0, che governano i meccanismi di creazione, diffusione e consumo degli avvisi di sicurezza all’interno dell’ecosistema CSAF 2.0. Comprendere chi sono gli stakeholder di CSAF e come i ruoli standardizzati definiti dal framework influenzano l’intero ciclo di vita delle informazioni sulle vulnerabilità è essenziale per i professionisti della sicurezza. Questo approfondimento aiuterà a comprendere meglio come funziona CSAF, come può essere utile per la propria organizzazione e come implementarlo efficacemente nel contesto della gestione delle vulnerabilità.
2. Chi sono gli stakeholder di CSAF?
A livello generale, il processo CSAF coinvolge due principali gruppi di stakeholder: i produttori a monte, che creano e distribuiscono avvisi di sicurezza informatica nel formato CSAF 2.0, e i consumatori a valle (utenti finali), che utilizzano questi avvisi per implementare le informazioni di sicurezza in essi contenute.
I produttori a monte includono fornitori di software come Cisco, e Oracle responsabili della sicurezza dei loro prodotti digitali e della divulgazione pubblica delle vulnerabilità identificate. Tra gli stakeholder a monte si annoverano anche ricercatori indipendenti e agenzie pubbliche come la Cybersecurity and Infrastructure Security Agency (CISA) negli Stati Uniti e l’Ufficio federale tedesco per la sicurezza delle informazioni (BSI), che fungono da fonti autorevoli per l’intelligence sulla sicurezza informatica.
I consumatori a valle includono sia società private che gestiscono direttamente la propria sicurezza informatica, sia , ovvero fornitori esterni che offrono servizi di monitoraggio e gestione della sicurezza in outsourcing. A valle, i team di sicurezza IT utilizzano le informazioni contenute nei documenti CSAF 2.0 per individuare vulnerabilità nell’infrastruttura e pianificare interventi di mitigazione. Allo stesso tempo, i dirigenti aziendali sfruttano questi dati per comprendere come i rischi IT potrebbero sulle operazioni aziendali.
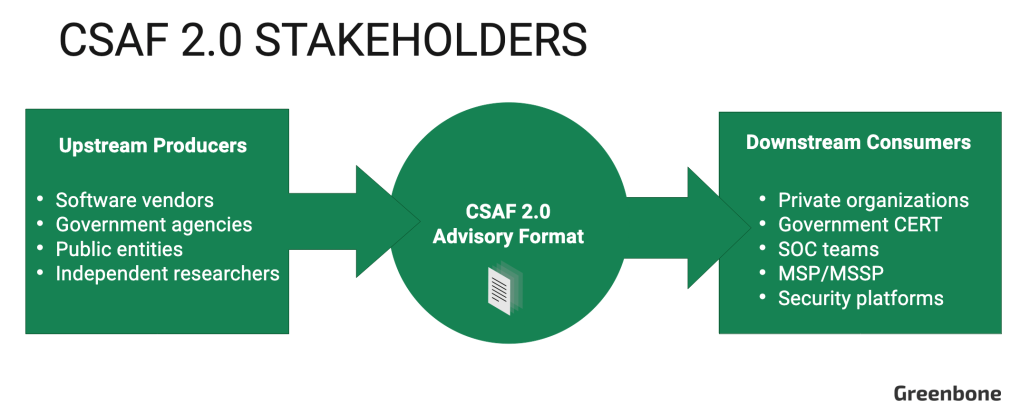
Flusso CSAF 2.0 dai produttori a monte ai consumatori a valle per avvisi di sicurezza di base
Lo standard CSAF 2.0 definisce ruoli specifici per i produttori a monte che delineano la loro partecipazione alla creazione e alla diffusione di documenti informativi. Esaminiamo più in dettaglio questi ruoli ufficialmente definiti.
2.1. I ruoli nel protocollo CSAF 2.0
I ruoli CSAF 2.0 sono definiti nella sezione 7.2. Si dividono in due gruppi distinti: i soggetti emittenti (“emittenti”) e gli aggregatori di dati (“aggregatori”). Gli emittenti sono direttamente coinvolti nella creazione di documenti informativi. Gli aggregatori raccolgono i documenti CSAF e li distribuiscono agli utenti finali, facilitando l’automazione per i consumatori. Sebbene una singola organizzazione possa ricoprire sia il ruolo di Emittente che quello di Aggregatore, è importante che queste due funzioni operino come entità distinte. Inoltre, le organizzazioni che agiscono come produttori a monte devono anche garantire la propria sicurezza informatica. Per questo motivo, possono svolgere il ruolo di consumatori a valle, utilizzando i documenti CSAF 2.0 per sostenere le proprie attività di gestione delle vulnerabilità.
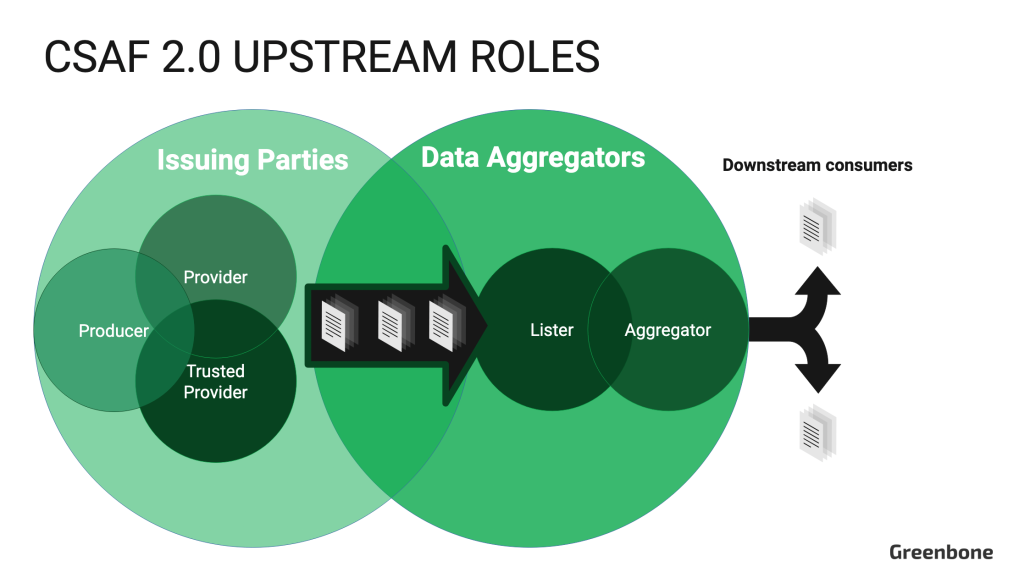
Diagramma che illustra la relazione tra i soggetti emittenti e gli aggregatori di dati CSAF 2.0.
Di seguito esaminiamo le responsabilità specifiche dei soggetti emittenti e degli aggregatori di dati CSAF 2.0.
2.1.1. Soggetti emittenti di CSAF 2.0
I soggetti emittenti sono responsabili della creazione degli avvisi di sicurezza informatica CSAF 2.0. Tuttavia, non sono responsabili per la trasmissione dei documenti agli utenti finali. Se i soggetti emittenti non desiderano che i loro avvisi vengano elencati o replicati dagli aggregatori di dati lo devono segnalare. Inoltre, i soggetti emittenti di CSAF 2.0 possono anche svolgere il ruolo di aggregatori di dati.
Di seguito le spiegazioni di ciascun ruolo secondario all’interno del gruppo dei soggetti emittenti:
2.1.1.1. Il ruolo di editore di CSAF
Gli editori sono generalmente organizzazioni che scoprono e comunicano avvisi esclusivamente per i propri prodotti digitali. Per adempiere al loro ruolo, gli editori devono rispettare i requisiti da 1 a 4 della sezione 7.1 della specifica CSAF 2.0. Questo implica la creazione di file strutturati con sintassi e contenuti validi, conformi alle convenzioni sui nomi dei file CSAF 2.0 descritte nella sezione 5.1, e la garanzia che i file siano accessibili solo tramite connessioni TLS crittografate. Inoltre, gli editori devono rendere pubblici tutti gli avvisi classificati come TLP:WHITE.
Gli editori devono inoltre mettere a disposizione del pubblico un documento provider-metadata.json contenente informazioni di base sull’organizzazione, sul suo stato di ruolo CSAF 2.0 e sui collegamenti a una chiave pubblica OpenPGP utilizzata per firmare digitalmente il documento provider-metadata.json e verificarne l’integrità. Queste informazioni vengono utilizzate da applicazioni software che, a valle, visualizzano gli avvisi dell’editore agli utenti finali.
2.1.1.2. Il ruolo di fornitore di CSAF
I fornitori rendono disponibili i documenti CSAF 2.0 alla comunità più ampia. Oltre a soddisfare gli stessi requisiti di un editore, un fornitore deve fornire il proprio file provider-metadata.json seguendo un metodo standardizzato (soddisfacendo almeno uno dei requisiti da 8 a 10 della sezione 7.1), utilizzare una distribuzione standardizzata per i suoi avvisi e implementare controlli tecnici per limitare l’accesso a qualsiasi documento informativo classificato come TLP:AMBER or TLP:RED.
I fornitori devono anche scegliere un metodo di distribuzione basato su directory o su ROLIE. In breve, la distribuzione basata su directory rende disponibili i documenti informativi all’interno di una normale struttura di percorsi di directory, mentre ROLIE (Resource-Oriented Lightweight Information Exchange) [RFC-8322] è un protocollo API RESTful progettato specificamente per automatizzare la sicurezza, la pubblicazione, la scoperta e la condivisione delle informazioni.
Se un fornitore utilizza la distribuzione basata su ROLIE, deve anche soddisfare i requisiti da 15 a 17 dalla sezione 7.1. In alternativa, se un fornitore utilizza la distribuzione basata su directory, deve rispettare i requisiti da 11 a 14 della sezione 7.1.
2.1.1.3. Il ruolo di trusted-provider di CSAF
I Trusted Provider sono una categoria speciale di provider CSAF che hanno raggiunto un elevato livello di fiducia e affidabilità. Devono rispettare rigorosi standard di sicurezza e qualità per garantire l’integrità dei documenti CSAF che emettono.
Oltre a soddisfare tutti i requisiti di un fornitore CSAF, i Trusted Provider devono anche rispettare i requisiti da 18 a 20 della sezione 7.1 della specifica CSAF 2.0. Questi requisiti comprendono la fornitura di un hash crittografico sicuro e di un file di firma OpenPGP per ciascun documento CSAF emesso, nonché la garanzia che la parte pubblica della chiave di firma OpenPGP sia resa pubblicamente disponibile.
2.1.2. Aggregatori di dati CSAF 2.0
Gli aggregatori di dati si occupano della raccolta e della ridistribuzione dei documenti CSAF. Funzionano come directory per gli emittenti CSAF 2.0 e i loro documenti informativi, fungendo da intermediari tra gli emittenti e gli utenti finali. Una singola entità può svolgere sia il ruolo di Lister che di aggregatore CSAF. Gli aggregatori di dati hanno la possibilità di scegliere quali avvisi degli editori upstream elencare, raccogliere e ridistribuire, in base alle esigenze dei loro clienti.
Di seguito la spiegazione di ciascun ruolo secondario all’interno del gruppo degli aggregatori di dati:
2.1.2.1. Il ruolo di lister CSAF
I lister raccolgono i documenti CSAF da più editori CSAF e li elencano in una posizione centralizzata per facilitarne il recupero. L’obiettivo di un lister è fungere da directory per gli avvisi CSAF 2.0, consolidando gli URL attraverso cui è possibile accedere ai documenti CSAF. Si presume che nessun lister fornisca un set completo di tutti i documenti CSAF.
I lister devono pubblicare un file aggregator.json valido che elenchi almeno due entità CSAF Provider separate. Sebbene un lister possa anche agire come parte emittente, non può elencare mirror che puntano a un dominio sotto il proprio controllo.
2.1.2.2. Il ruolo di aggregatore CSAF
Il ruolo di CSAF Aggregator rappresenta il punto finale di raccolta tra i documenti informativi CSAF 2.0 pubblicati e l’utente finale. Gli aggregatori offrono una posizione in cui i documenti CSAF possono essere recuperati da strumenti automatizzati. Sebbene gli aggregatori agiscano come una fonte consolidata di avvisi di sicurezza informatica, simile al NIST NVD o al CVE.org di The MITRE Corporation, CSAF 2.0 adotta un modello decentralizzato, in contrasto con un approccio centralizzato. Gli aggregatori non sono obbligati a fornire un elenco completo di documenti CSAF di tutti gli editori. Inoltre, gli editori possono scegliere di offrire l’accesso gratuito al loro feed di consulenza CSAF o di operare come servizio a pagamento.
Analogamente ai lister, gli aggregatori devono rendere un file aggregator.json disponibile pubblicamente. Inoltre, i documenti CSAF di ciascun emittente con mirroring devono essere organizzati in una cartella dedicata separata, contenente anche il file provider-metadata.json dell’emittente. Per adempiere al loro ruolo, gli aggregatori devono rispettare i requisiti da 1 a 6 e da 21 a 23 della sezione 7.1 della specifica CSAF 2.0.
Gli aggregatori CSAF sono responsabili di verificare che ogni documento CSAF replicato abbia una firma valida (requisito 19) e un hash crittografico sicuro (requisito 18). Se il soggetto emittente non fornisce questi file, l’aggregatore deve generarli.
3. Conclusione
Comprendere gli stakeholder e i ruoli di CSAF 2.0 è fondamentale per implementare correttamente la specifica e sfruttare i vantaggi della raccolta e del consumo automatizzati di informazioni critiche sulla sicurezza informatica. CSAF 2.0 identifica due principali gruppi di stakeholder: i produttori a monte, responsabili della creazione di avvisi di sicurezza, e i consumatori a valle, che utilizzano queste informazioni per migliorare la sicurezza. I ruoli definiti includono i soggetti emittenti (editori, fornitori e fornitori di fiducia) che generano e distribuiscono avvisi, e gli aggregatori di dati (lister e aggregatori) che raccolgono e diffondono questi avvisi agli utenti finali.
I membri di ogni ruolo devono rispettare specifici controlli di sicurezza per garantire la trasmissione sicura dei documenti CSAF 2.0. Inoltre, il Traffic Light Protocol (TLP) regola le modalità di condivisione dei documenti e definisce i controlli di accesso necessari per rispettare le autorizzazioni di distribuzione.